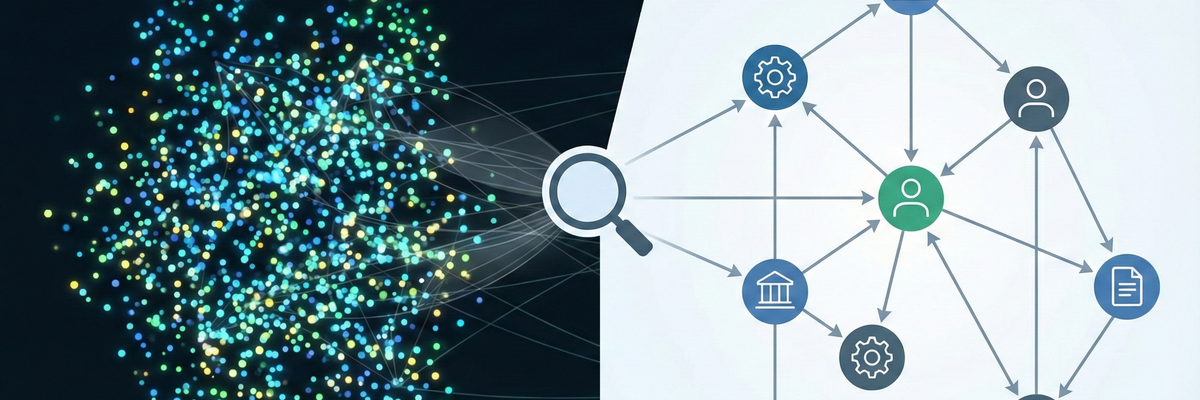
This is where GraphRAG comes into play - the next logical evolutionary step.
The deep dive: Why we need knowledge graphs (GraphRAG).
1. the problem: the "flatness" of vectors
Imagine you have thousands of PDF documents: contracts, emails, news reports. You ask your AI: "What is the risk for our project 'Alpha' due to the current delivery bottlenecks?"
Standard RAG: Searches for chunks containing the words "risk", "project alpha" and "delivery bottleneck". It may find a document that says: "Project Alpha needs steel."
The problem: The information that the steel supplier has just gone bankrupt is in a completely different email, without the word "Project Alpha" being mentioned there. The vector search sees no semantic similarity and misses the connection.
2. the solution: relationships instead of just similarity
GraphRAG combines the vagueness of vectors with the strict logic of knowledge graphs.
Instead of storing texts only as isolated points in space, we extract entities (people, companies, places) and their relationships (works for, delivers to, is part of).
3. the superpower: multi-hop reasoning
This is the real game changer. If documents have relationships, the AI can "hop" (make hops):
- Hop 1 (Document A): Project Alpha requires component X.
- Hop 2 (document B): Component X is manufactured by company Y.
- Hop 3 (Document C): Company Y files for bankruptcy.
A vector database sees three isolated facts. A knowledge graph sees a chain. GraphRAG can run through this chain and answer: "Attention: Your project is at risk because the supplier of your component is insolvent."
Conclusion: The future is hybrid
Vectors are unbeatable for unstructured similarity searches ("Find documents on topic X"). But for complex logic, compliance checks and real analysis across silos, we need graphs. The best systems of the future will not be either/or, but will combine both.
Question to the network: Have you experimented with knowledge graphs (e.g. Neo4j) in conjunction with LLMs, or are you still relying purely on embeddings?